КріптоПро
- Трохи про термінологію і класифікації
- Фіксування слабких параметрів Діффі-Хеллмана або як АНБ стежить за користувачами
- А чи все гаразд з генераторами випадковості?
- Архітектура сучасних генераторів випадкових чисел
- Dual_EC_DRBG
- Intel Secure Key
- Як погана випадковість поступово і непомітно "вбиває" RSA
- Висновок або як від усього цього захиститися
- література
Наше деловое партнерство www.banwar.org

У даній статті ми торкнемося сферу захисту інформації, яка останнім часом масово обговорюється на всіх рівнях - від газетних статей з кричущими заголовками до вузькоспеціалізованих форумів і серйозних наукових публікацій. Йтиметься про слабкості, навмисно внесених в системи захисту інформації - закладках.
Трохи про термінологію і класифікації
Слабкості в кріптосхеми, про які піде мова в цій статті, зазвичай називають "закладками". Термін "закладка" (що має, як може здатися, кілька сленговий відтінок) зафіксований в РФ на найвищому рівні (ГОСТ Р 51275-99, см. [1] ):
програмна закладка: Внесені до програмне забезпечення функціональні об'єкти, які за певних умов (вхідних даних) ініціюють виконання не описаних в документації функцій програмного забезпечення, що дозволяють здійснювати несанкціоновані дії на інформацію;
Незважаючи на численні приклади можливих випадків впровадження програмних і апаратних закладок, практично жоден з джерел не дає чітких відповідей на питання про точні механізми їх функціонування. Нижче ми розповідаємо про деякі можливі сценарії, які можуть використовуватися для того, щоб отримувати доступ до колосального обсягу зашифрованих даних у всьому світі, скориставшись помилками і приховані уразливості в криптографічних алгоритмах і протоколах. Існує безліч варіантів класифікації прихованих вразливостей, наведемо один з них:
- Дефекти, помилки реалізації (bugs) - ненавмисні помилки в реалізації криптографічних систем.
- Багдори (bugdoors = bugs & backdoors) - навмисна помилка в програмній реалізації, яка може виглядати як ненавмисна. Зазвичай в таких помилках легко заперечувати наявність злого умислу.
- Закладки (backdoors):
- Алгоритмічні закладки - навмисне приховане спотворення частини алгоритму програми, в результаті якого можлива поява у програмного компонента функцій, не передбачених специфікацією;
- Апаратні закладки - електронні пристрої / мікросхеми, таємно впроваджуються в елементи атакується інформаційної системи;
- Програмні закладки - внесені в програмне забезпечення функціональні об'єкти, які за певних умов ініціюють виконання не описаних в документації функцій.
Незалежно від способу впровадження, функціонування та впливу на систему, що атакується, всі ці уразливості так чи інакше можуть бути використані для здійснення несанкціонованого впливу на інформацію.
Основна увага в даній статті приділяється саме тих випадків, коли поява уразливості в системі можна пояснити навмисними діями з чиєїсь сторони. Найбільша проблема, пов'язана з такими уразливими, полягає в тому, що вони вкрай важко детектируются. Чим "глибше" рівень вбудовування закладки або багдора, тим складніше їх виявити. Закладки, впроваджені на етапі виробництва, практично не піддаються ніяким методам виявлення, а більшість прикладів їх виявлення грунтуються на чистої удачі.
Фіксування слабких параметрів Діффі-Хеллмана або як АНБ стежить за користувачами
У 2012 році Джеймс Бамфорд, посилаючись на анонімні джерела , Опублікував статтю, в якій говориться про те, що Агентство Національної Безпеки (АНБ) домоглося "обчислювальних проривів", які дали можливість зламувати поточні криптографічні системи з відкритим ключем. Роком пізніше в своїх заявах Едвард Сноуден торкнувся ту ж проблему, розповівши про створену АНБ програмі розвідки PRISM, що дозволяє дешіфровивать значну частину перехопленого інтернет-трафіку.
Однак жодне з цих заяв не давало відповідей на питання, як АНБ це робить, що викликало великі дискусії в інтернет-співтоваристві на тему бекдор і закладок в широко використовуваних криптографічних алгоритмах.
Ще в 1990-x роках був розроблений алгоритм факторизації цілих чисел під назвою "метод решета числового поля" або, як прийнято називати його в англомовній літературі, NFS-метод (number field sieve) [3] . Для криптографії він був цікавий тим, що дозволив (це зробила група вчених з Швейцарії, Японії, Франції, Нідерландів, Німеччини та США) успішно отримати доступ до даних, зашифрованих за допомогою 768-бітного ключа RSA [4] . Існували також роботи, що описують способи застосування даного підходу до задачі дискретного логарифмування (див., Наприклад, [5] ). Такі алгоритми вимагають більше часу в порівнянні з факторизації модулів RSA, що не дозволяє застосовувати їх для практично цікавих розмірів параметрів. Однак ефективність цих алгоритмів можна підвищити за рахунок попередніх обчислень, хоч і дуже трудомістких. Це і зробили чотирнадцять криптографов, які восени 2015 року опублікували статтю [20] , В якій NFS-метод, який використовує результати передвичесленням, був успішно застосований для вирішення завдання дискретного логарифмування і атаки на процедуру Діффі-Хеллмана.
Застосовуваний в роботі NFS-метод дає можливість для будь-якої фіксованої мультипликативной групи кінцевого поля відрахувань (по суті - для будь-якого простого числа p) провести процедуру передвичесленням, що дозволяє в подальшому швидко отримувати будь-який конкретний дискретний логарифм для кожного конкретного елемента в цій групі (тобто вирішувати щодо x рівняння gx = y mod p для будь-якого елемента y з групи). Це надає можливість доступу до виробляється в рамках процедури Діффі-Хеллмана секрету. Так, тижневі передобчислювання для одного 512-бітового простого числа p дали можливість знаходити конкретний дискретний логарифм у відповідній групі всього за одну хвилину.
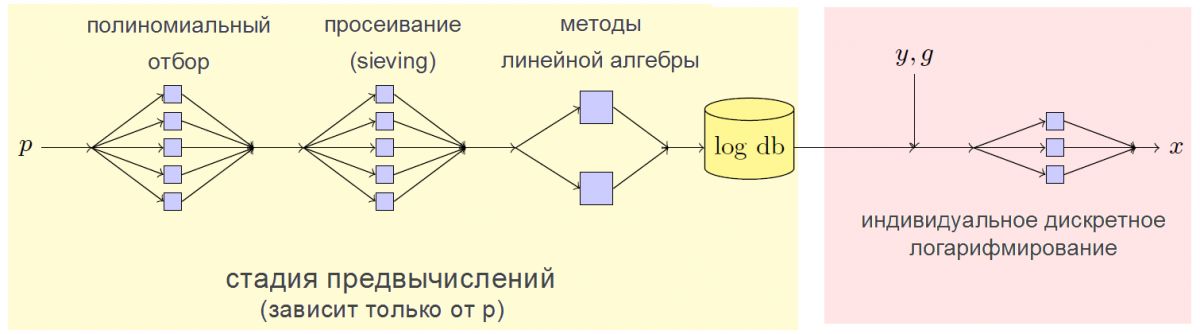
Варто відзначити, що NFS-метод не накладає ніяких додаткових обмежень на число p, а значить можна застосувати до будь-яких, навіть рекомендованим "стійким" групам. Більш того, його також можна застосовувати і до числам більшої розмірності, проте на це буде потрібно набагато більше обчислювальних ресурсів. Зокрема, необхідно кілька мільйонів доларів, щоб створити суперкомп'ютер, який за один рік повністю виконає процедуру передвичесленням для одного конкретного числа p найбільш часто використовується при захисті інформації користувачів довжини 1024 біта.
Автори статті звертають увагу на те, що, за даними Сноудена, неофіційний бюджет АНБ становить близько $ 10 млрд на рік, де більш ніж $ 1 млрд йде на експлуатацію комп'ютерної мережі. З огляду на це, агентству не складає труднощів здійснювати настільки дорогі операції.
Трудовитрати колосальні, можна подумати, адже простих чисел розмірності 512 біт, а тим більше 768 і 1024 біта величезна кількість. Однак в ході аналізу популярних інтернет-протоколів виявилося, що на поточний момент функціонують мільйони серверів, що використовують одні і ті ж групи.
У багатьох реалізаціях прості числа або зашиті в код, або постійно переіспользуются одні й ті ж набори рекомендованих безпечних простих чисел. Як приклад подібних наборів можна привести так звані групи Оуклі: (Oakley Group 1 (768 bit), Oakley Group 2 (1024 bit), Oakley Group 5 (тисяча п'ятсот тридцять шість bit)). Подібні рекомендації створювалися для того, щоб виключити можливість використання "слабких" груп, до яких застосовні різні відомі методи швидкого знаходження дискретного логарифма. Інша причина - бажання протистояти UKS-методам (зокрема, використовуються в атаці на TLS TLS triple handshake ), Що полягає в можливості порушника підтримувати кілька з'єднань на одному ключі - зокрема, в разі мультиплікативний груп полів відрахувань це можливо робити, підбираючи параметри групи. У більшій частині HTTPS (TLS), IPsec і SSH-з'єднань використовуються менше десятка простих чисел.
Таким чином, мета виправдовує засоби. Перевирахованой, виконане для одного з простих чисел, дозволить проводити пасивний перехоплення повідомлень 18% сайтів з підтримкою HTTPS, а для іншого дозволить дешіфровивать трафік 66% IPsec VPN-з'єднань і 26% SSH-серверів. Подібні витрати на обчислення одного модуля є, таким чином, більш ніж розумною інвестицією для державних спецслужб. Самі дослідники порівнюють даний випадок з «Криптоаналіз Енігми під час Другої Світової».
Генерація неповторяющихся простих чисел в процедурі Діффі-Хеллмана не гарантує захисту від атак з використанням NFS-методу, якщо довжини параметрів малі. Як приклад можна привести вразливість TLS під назвою Logjam, пов'язану з нав'язуванням наборів шифрування DHE_EXPORT і використання при узгодженні ключів мультиплікативний груп полів по 512-бітовому модулю.
Таким чином, стає можливим істотно знижувати стійкість протоколу. Проробивши передобчислювання для найбільш поширених простих 512-бітних чисел, зловмисник може отримати можливість в режимі реального часу зламувати TLS-з'єднання, залишаючись непоміченим.
Хоча на подібне поки немає прямих доказів, застосування передвичесленням для прискорення злому процедури Діффі-Хеллмана при використанні фіксованих 1024-бітових модулів - це цілком правдоподібна теорія, що пояснює, яким чином може функціонувати програма PRISM.
А чи все гаразд з генераторами випадковості?
Якісні випадкові і псевдовипадкові послідовності грають величезну роль при використанні криптографічних засобів, і часто від них повністю залежить стійкість системи. Можна навести такі приклади випадків, в яких використання поганого джерела випадковості призводить до краху безпеки всієї системи:
- використання одного і того ж значення в якості випадкового параметра в алгоритмах підпису DSA, ECDSA, ГОСТ Р 34.10-94, ГОСТ Р 34.10-2001, ГОСТ Р 34.10-2012 при обробці двох різних повідомлень на одному ключі дозволяє відновити секретні ключі підпису і підробляти підпис . Подібна помилка в реалізації ECDSA була успішно використана при обході захисту в Sony PlayStation 3 ;
- Використання одного і того ж випадкового набору в якості сінхропосилкі (IV) поточних шифрів або блокових шифрів, що працюють в режимах CFB або гамування, призводить до перекриття гами і до можливості відновлення частин відкритого тексту. Подібне вже траплялося в реальних системах - неправильне використання шифру RC4 дозволяло відновити частини документів MS Word і Excel по послідовності Автозбереження копій (див. [6] ).
Однією з вимог до генератора випадкових і псевдовипадкових чисел є непередбачуваність - тобто неможливість по деякому вихідному відрізку послідовності дізнатися, яка псевдослучайная послідовність буде на виході генератора в подальшому. Ця вимога дуже важливо не тільки в теорії, а й на практиці, так як секретні дані (ключі схеми) і відкриті сінхропосилкі зазвичай генеруються одним і тим же генератором без переініціалізація, що дає можливість зловмиснику знати фрагменти його виходу заздалегідь.
Архітектура сучасних генераторів випадкових чисел
Типова архітектура генератора випадкових послідовності складається з двох частин: джерела "справжньою" ентропії TRNG (True Random Number Generator) і детермінованого генератора DRBG (Deterministic Random Number Generator). Поділ на два компонента обумовлено тим, що TRNG зазвичай працює повільно і не завжди дає можливість якісно проконтролювати коректність його роботи. Другий шар DRBG працює набагато швидше, так як є детермінованим генератором, в основі якого лежить певний алгоритм, який бере на вхід початкове значення (seed) і розвертає його в довгу псевдослучайную послідовність із заздалегідь визначеними властивостями. Під детерминированностью генератора мається на увазі те, що початкове значення завжди розгортається в одну і ту ж послідовність. Від того, наскільки складно по виходу цього шару відновити початкове значення і внутрішній стан генератора, залежить стійкість системи.
Розглянемо тепер кілька прикладів, які показують, як закладки можуть бути впроваджені в генератори випадкових чисел.
Dual_EC_DRBG
Dual_EC_DRBG - детермінований генератор псевдовипадкових послідовностей, який був розроблений фахівцями АНБ і після деяких змін був стандартизований NIST. Деякий час по тому Фергюсон і Шумов помітили, що при знанні певних секретних властивостей констант, що визначають генератор, по його виходу можна визначити послідовності, які він видасть в процесі подальшої роботи. Мабуть, серед відомих цей випадок є найближчою до того, що можна назвати алгоритмічної закладкою, - величезна кількість обставин вказує на навмисне просування АНБ цього генератора зі спеціальними фіксованими константами в NIST.

Слід зазначити наступні цікаві моменти. По-перше, якщо уважно придивитися до схеми роботи, то видно, що знання співвідношення між точками P і Q, тобто знання такого d, що P = dQ, дозволяє, спостерігаючи один повний блок виходу (30 байт), відновити внутрішній стан генератора , за умови відсутності додаткового введення (Additional Input). Принцип роботи даної закладки зображений на схемі пунктиром. По-друге, в 2005 році кілька членів комітету зі стандартизації подали заявку на патент , В якому була описана схема генератора Dual_EC_DRBG і приклад його використання для депонування ключів (key escrow). По-третє, параметри для даного генератора були обрані співробітниками АНБ, при їх генерації не використовувалася принцип "перевіряється випадковості" і вони увійшли в нормативне уявлення стандарту, тобто були обов'язкові до використання, а не просто служили для перевірки коректності реалізації.
Intel Secure Key
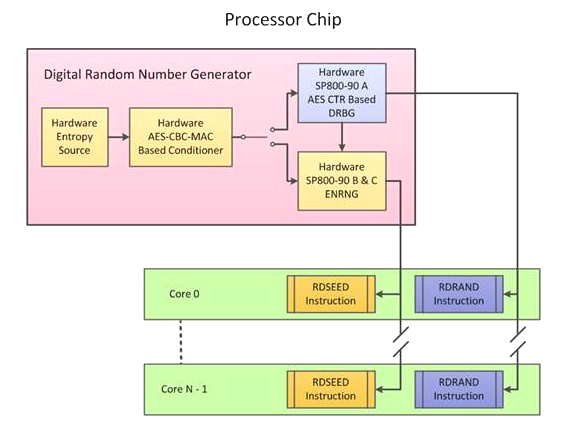
Технологія генерації випадкових чисел Intel Secure Key, також відома як Bull Mountain, була розроблена дослідницьким центром Intel's Circuit Research Lab і впроваджена в процесори, починаючи з архітектури Ivy Bridge. Вона містила дві інструкції процесора - RDSEED і RDRAND, що спираються на апаратні джерела ентропії (по крайней мере, так заявляють розробники Intel). Перша функція генерує початкове значення для датчика псевдослучайной послідовності, друга - є тим самим генератором DRBG, який видає блок псевдовипадкових даних, використовуючи результат роботи RDSEED.
Деяка інформація про те, як цей функціонал реалізований в процесорах, є в документації Intel [7] . У загальних рисах алгоритм роботи описується наступним чином: дві пари чисел по 256 біт, отриманих з апаратного джерела ентропії, передаються в апаратний блок, який виконує криптографічний алгоритм AES в режимі вироблення імітовставки AES-CBC-MAC.
Розробники Intel стверджували, що дані інструкції мали гарні статистичними властивостями і працювали досить швидко. Однак у світлі недавнього скандалу з впровадженням бекдора АНБ в Dual_EC_DRBG, описаного нами в попередньому розділі, багато хто підозрював Bull Mountain в наявності тих чи інших закладок. Так, наприклад, колишній розробник ядра Linux стверджував , що пішов з роботи через впровадження в їх ДСЧ-модуль інструкції RDRAND від Intel.
У відповідь на ці заяви творець ядра Linux Лінус Торвальдс висловив досить різкий аргумент на користь безпеки свого продукту: "Коротка відповідь: ми знаємо, що ми робимо. Ви - ні. Розгорнуту відповідь: ми використовуємо RDRAND як один з багатьох джерел вхідних даних в пулі випадкових чисел і ми використовуємо його для підвищення випадковості цього набору. Так що навіть якщо в RDRAND є бекдор від АНБ, наш спосіб використання RDRAND в реальності покращує якість набору випадкових чисел, який ви отримуєте з / dev / random ".
Однак в 2013 році Тейлор Хорнбі представив прототип реалізації інструкції RDRAND для впровадження закладки в роботу пристрою / dev / random в ядрі Linux.
Якщо завантажити версію 3.12.8 коду ядра Linux, то у файлі drivers / char / random.c можна знайти функцію extract_buf (), яка використовується при читанні з / dev / random. Нижче наведено фрагмент її коду:
for (i = 0; i <LONGS (EXTRACT_SIZE); i ++) {
unsigned long v;
// arch_get_random is RDRAND.
if (! arch_get_random_long (& v))
break;
hash.l [i] ^ = v;
Здавалося б, Лінус Торвальдс мав цілковиту рацію в своїх заявах, адже навіть якщо припустити, що RDRAND в процесі роботи видає погану передбачувану послідовність, якісний ентропійний пул, вироблений раніше і використовується в функції хешування, компенсує цю уразливість.
За словами Хорнбі, дана схема є стійкою тільки в теорії, на практиці ж під час виконання інструкції RDRAND хеш-значення знаходиться в пам'яті комп'ютера і з великою ймовірністю в кеші процесора, а, значить, на етапі своєї роботи RDRAND може (в обхід офіційних інструкцій своєї роботи) в якості вихідного значення взяти, наприклад, Інвертований значення хеша. Для того, щоб вироблювана послідовність здавалася випадковою, звичайно, потрібно буде використовувати більш складно влаштовану функцію від хеша, ніж просте інвертування. Для реалізації даного підходу необхідно лише отримати доступ до регістру, яка вказує на область стека, в якій зберігається це хеш-значення.
Використовуючи Bochs (емулятор процесора), Хорнбі представив реалізацію інструкції RDRAND на мові C ++, код доступний будь-якому охочому .
Деякі дослідники вважають, що такий механізм досить складно реалізувати на практиці, працювати він буде довго і набагато простіше зробити так, щоб інструкція RDRAND використовувала алгоритм шифрування AES з ключем, відомим тільки розробникам закладки. В цьому випадку пристрій / dev / random не постраждає, але атаці можуть бути схильні ті додатки, які використовують результати роботи RDRAND безпосередньо, що заохочується розробниками процесора (наприклад, коментар David Johnson з Intel).
Виходячи з документації Intel, один виклик інструкції RDRAND займає 150 тактів, чого в цілому достатньо для здійснення подібної атаки і труднощі визначення наявності закладки за часом виконання.
Факт, що деякий функціонал в процесорах Intel реалізований за допомогою оновлюваного микрокода, додає ще більше підозр, так як закладка може бути впроваджена в певну партію процесорів на етапі виробництва або ж разом з оновленням микрокода.
Далі розглядається незвичайний приклад того, як використання "поганий випадковості" може призводити до появи ключів, які становлять небезпеку один для одного.
Як погана випадковість поступово і непомітно "вбиває" RSA
Основна ідея злому алгоритму RSA, використаного спільно з поганим генератором випадкових чисел, заснована на обчисленнях найбільших спільних дільників (НОД) використовуваних модулів. Припустимо, нам дано два модуля RSA N1 = p1 · q1 і N2 = p2 · q2, що є твором двох простих чисел. Якщо вони мають один загальний простий множник (далі розділений множник) p1 = p2 = p, то, вважаючи НСД (N1, N2), ми отримаємо значення p, а значить легко вирішимо завдання факторизації обох ключів, знайшовши їх подільники. Прості числа, твір яких є модулем RSA, генеруються відповідно до деякої процедурою, що включає генерацію випадкових чисел. Якщо кілька серверів використовували для цього погані генератори, то ймовірність збігу одного із співмножників у двох модулів RSA сильно зростає. Оскільки модуль RSA є частиною відкритого ключа, у зловмисника є можливість створити базу цих модулів, обробити її і зламати за допомогою вказаного вище методу частина RSA-ключів.

З теореми про розподіл простих чисел слід, що існує близько 10151 простих чисел розмірності 512 біт. Навіть якщо взяти мільярди випадково згенерували модулів RSA, шанс зустріти нетривіальний НСД вкрай малий.
Однак в реальності множники, твір яких є модулем RSA, генеруються далеко не завжди чисто випадковими. Більш того, один і той же просте число p часто повторюється безліч разів. у статті [8] , Опублікованій лабораторією Ленстра, автори зібрали велику базу доступних ключів і сертифікатів. Проаналізувавши її, вчені прийшли до висновку, що з тисячі перевірених модулів RSA в середньому два є небезпечними. Був створений спеціальний сервіс , Що дозволяє всім користувачам перевірити свої модулі.
Трохи пізніше команда вчених з коледжу Ройял Холлоуей Лондонського Університету провела дослідження (див. [9] ), В ході яких в загальнодоступних мережах були знайдені великі кластери слабких модулів RSA, що мають спільні множники. Один простий множник зустрічався 28394 рази, ще два - більше 1000 разів, а в цілому 1 176 множників повторювалися 100 або більше разів кожен. За даними вчених, виникнення множника, що повторюється більш ніж 28000 раз, було пов'язано з широкосмуговим маршрутизатором з модулем SSL VPN - іншими словами, можна говорити про помилку або, можливо, навмисне багдоре реалізації, в якій генерувалося одне число і вшивається в пристрій.
Подібні цифри дали більш ніж серйозні підстави для пошуку вразливостей, пов'язаних з поділом загального простого множника в модулях RSA. Однак розмір реальних баз модулів варіюється від 106 до 1013 елементів. Це призводить до того, що час обробки даних стає неприпустимо великим, і навіть при використанні найшвидших реалізацій алгоритму знаходження НСД двох чисел для знаходження НСД всіх пар модулів засобами користувальницької обчислювальної машини для деяких баз потрібно близько 30 років.
Однак існує ряд більш ефективних методів (див. [10] ), Спрямованих на обробку великих масивів модулів RSA. Їх застосування дає можливість вирішувати подібні завдання за допомогою ресурсів звичайної лабораторії, не кажучи вже про можливості державних структур.
Висновок з цих даних як і раніше можна винести наступний: жоден стійкий алгоритм не забезпечить користувачам потрібного рівня безпеки, якщо в ньому некоректно генеруються або використовуються його параметри.
Висновок або як від усього цього захиститися
Як же уникнути впровадження закладок? Крім очевидних рекомендацій щодо дотримання всіх вимог до експлуатації кріптосредств (наприклад, по правильного налаштування датчиків випадкових чисел) наведемо кілька принципів, які дозволяють захиститися хоча б від частини відомих на сьогоднішній день методів впровадження алгоритмічних закладок (або переконатися, що закладок немає):
- Використовувати перевірені групи. Необхідно розуміти, що не всі циклічні групи однаково безпечні - наприклад, в групі чисел {0, ..., n-1} з операцією додавання по модулю n задача дискретного логарифмування вирішується тривіальним розподілом, яке виконується майже миттєво. З урахуванням того, що було описано на початку цієї статті, використання мультиплікативної групи кінцевого простого поля також викликає певні побоювання. На сьогоднішній день найбільш надійними в плані не тільки завдання дискретного логарифмування, а й інших важливих завдань (обчислювальної і розпізнавального завдань Діффі-Хеллмана) представляються групи точок еліптичних кривих, визначених над простим кінцевим полем, обраних з урахуванням вимог стійкості до всіх існуючих методів криптоаналізу ( см., наприклад, [2] и [15] ).
- Якщо фіксувати "підозрілі" групи, то хоча б великі. При використанні (і вже тим більше при стандартизації) криптографічних параметрів необхідно враховувати не тільки існуючі на сьогоднішній день методи криптоаналізу, а й враховувати тенденцію до збільшення потужності обчислювальної техніки і розвитку відомих методів. Так, більш-менш стійким з урахуванням деякої перспективи може вважатися модуль RSA довжиною від 3072 біт (див. [11] ). При цьому вважається, що приблизно тим же рівнем стійкості володіє група точок еліптичної кривої потужності від 2256 (тобто 256 біт).
- Використовувати рішення без прихованих елементів структури. Закладки, на зразок тієї, яка була виявлена в датчику Dual_EC_DRBG, показують важливість використання принципу "доказовою псевдовипадковий" при породженні тих чи інших криптографічних параметрів. Це означає, що крім пред'явлення конкретних значень, творці специфікації повинні описати процедуру, за допомогою якого ці значення були отримані. При цьому принципи побудови даного алгоритму повинні бути ясні і зрозумілі.
Відзначимо, що в Росії не стандартизовані криптосистеми, засновані на завданні дискретного логарифмування в кільцях відрахувань (до яких відноситься і RSA), а від використання простих полів при підпису і виробленні ключів відмовилися ще в 2001 році [12] . На даний момент в РФ стандарт електронного підпису передбачає використання груп точок еліптичних кривих над полями розміру 256 і 512 біт. Принцип доказовою псевдовипадковий став де-факто обов'язковим до застосування для вітчизняних фахівців. Так, він використовувався (див. [13] ) При виробленні параметрів алгоритму Стрибог, прийнятого в якості стандарту функції хешування [14] . Також даний принцип використовується при виробленні параметрів алгоритмів, що фіксуються в якості рекомендацій по стандартизації Технічного комітету зі стандартизації "Криптографічний захист інформації" (ТК 26) (див., Наприклад, [15] и [2] ). Детально про те, як вироблялися параметри еліптичних кривих, розказано в статтях [16] и [17] , Опублікованих раніше в нашому блозі. Що стосується прихованого переходу на роботу зі слабкими параметрами за аналогією з атакою Logjam, то для вітчизняних протокольних рішень це неможливо, тому що в них просто немає слабких параметрів. Всі параметри протоколу TLS обрані таким чином, щоб забезпечувати стійкість з великим запасом (див. [18] и [19] ).
На закінчення зазначимо таке важлива обставина. Відповідь на питання, чи є та чи інша слабкість схеми навмисно привнесеної, багато в чому залежить від того, наскільки відповідає на це питання є прихильником теорії змови. Тому остаточне судження про те, чи є та чи інша слабкість закладкою (тобто, закладена вона навмисно), читач повинен винести сам.
Автори висловлюють подяку Мошнин Д.А. і Миколаєву В.Д. за цінні зауваження та конструктивну критику.
література
[1] ГОСТ Р 51275-99 «Захист інформації. Об'єкт інформатизації. Фактори, що впливають на інформацію. Загальні положення".
[2] Інформаційна технологія. Кріптографічній захист інформації. Рекомендації по стандартизації. Завдання параметрів еліптичних кривих відповідно до ГОСТ Р 34.10-2012. http://www.tc26.ru/methods/recommendation/%D0%A2%D0%9A26%D0%AD%D0%9A.pdf
[3] JP Buhler, Jr. HW Lenstra, and Carl Pomerance. Factoring integer with the number field sieve. In "The development of the number field sieve", volume 1554 of Lecture Notes in Mathematics. pages 50-94. Springer-Verlag, 1993. http://link.springer.com/chapter/10.1007%2FBFb0091539
[4] Kleinjung T., Aoki K., Franke J., Lenstra AK, Thome E., Bos JW, Gaudry P., Kruppa A., Montgomery PL, Osvik DA, Herman te Riele, Timofeev A., Zimmermann P. Factorization of a 768-bit RSA modulus. https://eprint.iacr.org/2010/006.pdf .
[5] Gordon D. Discrete Logarithms in GF (p) using the number field sieve, SIAM J Discrete Math. 6 (1993), 124-138. http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.106.8844&rep=rep1&type=pdf
[6] Hongjun Wu, The Misuse of RC4 in Microsoft Word and Excel. https://eprint.iacr.org/2005/007.pdf
[7] Intel Digital Random Number Generator (DRNG), Software Implementation Guide, Revision 1.1, August 7, 2012. https://software.intel.com/sites/default/files/m/d/4/1/d/8/441_Intel_R__DRNG_Software_Implementation_Guide_final_Aug7.pdf
[8] Lenstra AK, Hughes JP, Augier M., Bos JW, Kleinjung T., Wachter C. Ron was wrong, Whit is right. http://infoscience.epfl.ch/record/174943/files/eprint.pdf
[9] Albrecht MR, Papini D., Paterson KG and Villanueva-Polanco R., Factoring 512-bit RSA Moduli for Fun (and a Profit of $ 9,000). https://martinralbrecht.files.wordpress.com/2015/03/freak-scan1.pdf
[10] Cloostermans B. Quasi-linear GCD computation and factoring RSA moduli. Eindhoven: Technische Universiteit Eindhoven, 2012. http://alexandria.tue.nl/extra1/afstversl/wsk-i/cloostermans2012.pdf
[11] NIST Special Publication 800-57 Recommendation for Key Management - Part 1: General - Barker E., Barker W., Burr W., Polk W., Smid M., Gallagher PD, Under Secretary For 2012. http://csrc.nist.gov/publications/nistpubs/800-57/sp800-57_part1_rev3_general.pdf
[12] Інформаційні технології. Кріптографічній захист інформації. Процеси формування та перевірки цифрового підпису. ГОСТ Р 34.10-2001, Державний Стандарт Російської Федерації.
[13] Рудська В.І. Про алгоритм вироблення констант функції хешування «Стрибог». https://www.tc26.ru/ISO_IEC/Streebog/streebog_constants_rus.pdf
[14] ГОСТ Р 34.11-2012. Інформаційна технологія. Кріптографічній захист інформації. Функція хешування.
[15] Інформаційна технологія. Кріптографічній захист інформації. Рекомендації по стандартизації. Завдання параметрів скручених еліптичних кривих Едвардса. http://www.tc26.ru/methods/recommendation/CPECC14-TC26.pdf
[16] Смишляєв С.В., Ошкін І.Б., Алексєєв Е.К., Соніна Л.А. Скорочення еліптичні криві Едвардса: коли, навіщо, для кого? http://www.cryptopro.ru/blog/2014/12/04/skruchennye-ellipticheskie-krivye-edvardsa-kogda-zachem-dlya-kogo
[17] Смишляєв С.В. Еліптичні криві для нового стандарту електронного підпису. http://www.cryptopro.ru/blog/2014/01/21/ellipticheskie-krivye-dlya-novogo-standarta-elektronnoi-podpisi
[18] Смишляєв С.В., Алексєєв Є.К. Методичні рекомендації ТК 26: алгоритми, сертифікати, CMS, TLS. http://www.cryptopro.ru/blog/2014/07/07/metodicheskie-rekomendatsii-tk-26-algoritmy-sertifikaty-cms-tls
[19] Інформаційна технологія. Кріптографічній захист інформації. Рекомендації по стандартизації. Використання наборів алгоритмів шифрування на основі ГОСТ 28147-89 для протоколу безпеки транспортного рівня (TLS). http://www.tc26.ru/methods/recommendation/%D0%A2%D0%9A26TLS.pdf
[20] Adrian D., Bhargavan K., Durumeric Z., Gaudry P., Green M., Halderman JA, Heninger N., Springall D., Thome E., Valenta L., VanderSloot B., Wustrow E., Zanella-Béguelin S., Zimmermann P. Imperfect Forward Secrecy: How Diffie-Hellman Fails in Practice. https://weakdh.org/imperfect-forward-secrecy-ccs15.pdf
Смишляєв С.В., к.ф.-м.н.,
начальник відділу захисту інформації
ТОВ "крипто-ПРО"
Алексєєв Е.К., к.ф.-м.н.,
провідний інженер-аналітик
ТОВ "крипто-ПРО"
Смишляєва Е.С.,
інженер-програміст 3 категорії
ТОВ "крипто-ПРО"
Сидоров Е.С.,
незалежний експерт
А чи все гаразд з генераторами випадковості?Edu/viewdoc/download?
Скорочення еліптичні криві Едвардса: коли, навіщо, для кого?